We are working on knowledge base concept design, development of elemental AI technologies, and workflow development, aiming to construct a knowledge base specialized in smart cell development and to develop AI technologies that support the knowledge base construction.
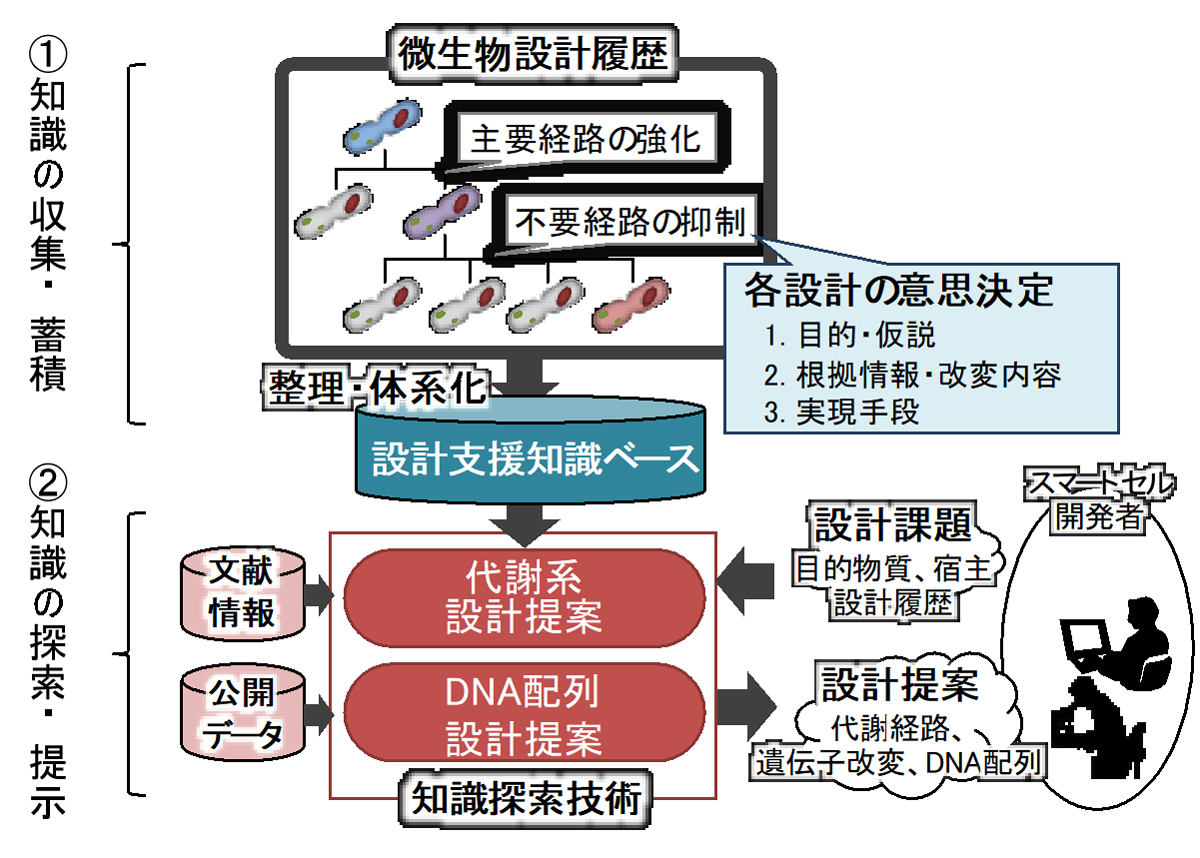
The construction of a knowledge base requires the development of two main processes (Fig. 1). That is, (1) knowledge collection and accumulation: the process of accumulating various trial-and-error results in the past smart cell development as reusable "knowledge" by organizing the relations among the events, (2) knowledge search and presentation: the process of presenting information on events, hypotheses, causal relationships, or reference literature that supports interpretation or decision-making by the user, from the accumulated knowledge, in response to the queries of the smart cell developers (users).
For Process (1), we are organizing and systematizing the history of strain modifications that have been conducted to realize the desired smart cells, namely, the design history. More specifically, contents of the decision-making in the preparation of each modified strain are normalized in terms of "purposes of the modification and hypothesis," "information that serves as a basis and contents of modification," and "means for achieving the modification (means for synthesis and verification)" and stored in the database engine.
The constructed database is utilized for cross-sectional search in terms of the "purposes of the strain modification," "modification contents," or "means for the modification" in the knowledge extraction process described later. In addition, by hierarchically organizing the derivational relations from the parent strain that is the origin of the modification, some effects, such as becoming aware of overlooked modifications or experiments and supporting the idea of new design hypotheses based on such awareness, are expected. In Process (2), we are developing a knowledge search technology that presents design proposals to the user by searching the database for the knowledge relevant to the query entered by the user through the operation terminal. More specifically, it is a technology in which, using the target material/host and the history of designs conducted so far as a query, information highly related to the contents of the query is cross-sectionally searched from the information accumulated in the database, literature, etc., and the searched knowledge, such as a metabolic pathway, gene modification, and DNA sequence, is presented to the user in an easy-to-understand format.
Strengths in the Industrial Arena
This technology allows exhaustive and comprehensive processing of a huge amount of knowledge from literature and publicly accessible data in a short time, as well as proposal of the standard design of smart cells. It is also expected to propose a "serendipitous" design principle. Thus, the technology can contribute to the acceleration of smart cell creation.

